Hierarchical Object Map Estimation for Efficient and Robust Navigation (2021)
click to enlarge
Hierarchical representation of objects for improved monocular navigation
Paper: http://groups.csail.mit.edu/rrg/papers/ok_icra21.pdf
Video: https://youtu.be/E-Y0RizgFBs, Talk: https://youtu.be/itxJeavfhvs
We propose a hierarchical model of objects, where the representation of each object is allowed to change based on the quality of accumulated measurements. We initially estimate each object as a 2D bounding box or a 3D point, encoding only the geometric properties that can be well-constrained using limited viewpoints. With additional measurements, we allow each object to become a higher dimensional 3D volumetric model for improved reconstruction accuracy and collision-testing. HOME is robust to deficiencies in viewpoints and allows planning safe and efficient trajectories around object obstacles using a monocular camera.
Paper: http://groups.csail.mit.edu/rrg/papers/ok_icra21.pdf
Video: https://youtu.be/E-Y0RizgFBs, Talk: https://youtu.be/itxJeavfhvs
We propose a hierarchical model of objects, where the representation of each object is allowed to change based on the quality of accumulated measurements. We initially estimate each object as a 2D bounding box or a 3D point, encoding only the geometric properties that can be well-constrained using limited viewpoints. With additional measurements, we allow each object to become a higher dimensional 3D volumetric model for improved reconstruction accuracy and collision-testing. HOME is robust to deficiencies in viewpoints and allows planning safe and efficient trajectories around object obstacles using a monocular camera.
VoluMon: Weakly-Supervised Volumetric Monocular Estimation with Ellipsoid Representations (2021)

click to enlarge
Weakly supervised volumetric monocular estimation that requires annotations in the image space only
Paper: http://groups.csail.mit.edu/rrg/papers/liu_ok_iros_2021_camera_ready.pdf
Video: https://youtu.be/w8DCRvjApCc
We present VoluMon that requires annotations in the image space only, i.e., associated object bounding box detections and instance segmentation. By approximating object geometry as ellipsoids, we can exploit the dual form of the ellipsoid to optimize with respect to bounding box annotations and the primal form of the ellipsoid to optimize with respect to a segmented pointcloud. For a simulated dataset with access to ground-truth, we show monocular object estimation performance similar to a naive online depth based estimation approach and after online refinement when depth images are available, we also approach the performance of a learned deep 6D pose estimator, which is supervised with projected 3D bounding box keypoints and assumes known model dimensions.
Paper: http://groups.csail.mit.edu/rrg/papers/liu_ok_iros_2021_camera_ready.pdf
Video: https://youtu.be/w8DCRvjApCc
We present VoluMon that requires annotations in the image space only, i.e., associated object bounding box detections and instance segmentation. By approximating object geometry as ellipsoids, we can exploit the dual form of the ellipsoid to optimize with respect to bounding box annotations and the primal form of the ellipsoid to optimize with respect to a segmented pointcloud. For a simulated dataset with access to ground-truth, we show monocular object estimation performance similar to a naive online depth based estimation approach and after online refinement when depth images are available, we also approach the performance of a learned deep 6D pose estimator, which is supervised with projected 3D bounding box keypoints and assumes known model dimensions.
Search and rescue under the forest canopy using multiple UAVs (2020)

click to enlarge
Multi-robot system for GPS-denied search and rescue under the forest canopy
Paper: https://journals.sagepub.com/doi/pdf/10.1177/0278364920929398
Video: https://youtu.be/2hRNx_0SWGw
Our proposed system features unmanned aerial vehicles (UAVs) that perform onboard sensing, estimation, and planning. When communication is available, each UAV transmits compressed tree-based submaps to a central ground station for collaborative simultaneous localization and mapping (CSLAM). To overcome high measurement noise and perceptual aliasing, we use the local configuration of a group of trees as a distinctive feature for robust loop closure detection. Furthermore, we propose a novel procedure based on cycle consistent multiway matching to recover from incorrect pairwise data associations. The proposed multi-UAV system is validated both in simulation and during real-world collaborative exploration missions at NASA Langley Research Center.
Paper: https://journals.sagepub.com/doi/pdf/10.1177/0278364920929398
Video: https://youtu.be/2hRNx_0SWGw
Our proposed system features unmanned aerial vehicles (UAVs) that perform onboard sensing, estimation, and planning. When communication is available, each UAV transmits compressed tree-based submaps to a central ground station for collaborative simultaneous localization and mapping (CSLAM). To overcome high measurement noise and perceptual aliasing, we use the local configuration of a group of trees as a distinctive feature for robust loop closure detection. Furthermore, we propose a novel procedure based on cycle consistent multiway matching to recover from incorrect pairwise data associations. The proposed multi-UAV system is validated both in simulation and during real-world collaborative exploration missions at NASA Langley Research Center.
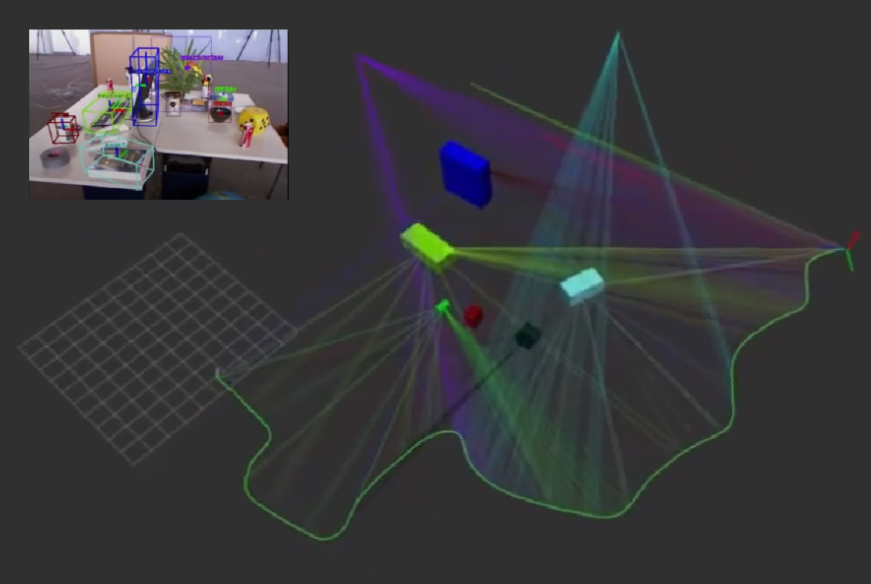
Robust Object-based SLAM for High-speed Autonomous Navigation (2019)
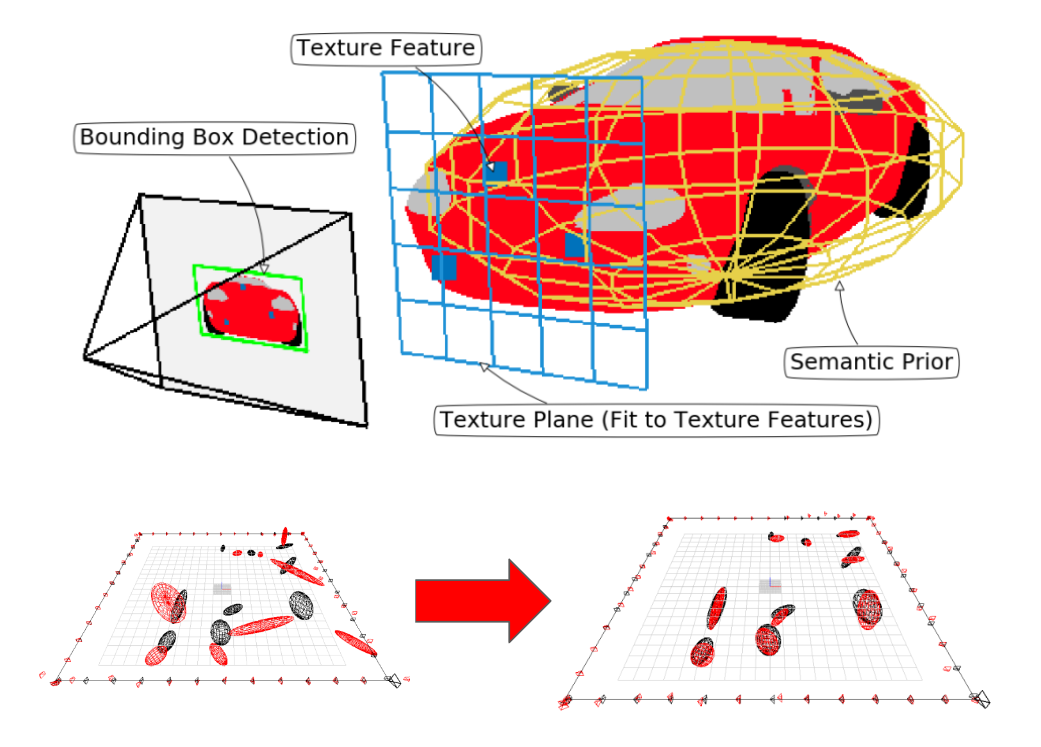
click to enlarge
Monocular object-level mapping suitable for autonomous navigation
Paper: https://groups.csail.mit.edu/rrg/papers/OkLiu19icra.pdf
We represent objects as ellipsoids and infer their parameters using three sources of information – bounding box detections, image texture, and semantic knowledge – to overcome the observability problem in ellipsoid-based SLAM under common forward-translating vehicle motions. Each bounding box provides four planar constraints on an object surface and we add a fifth planar constraint using the texture on the objects
along with a semantic prior on the shape of ellipsoids. We demonstrate ROSHAN in simulation where we outperform the baseline, reducing the median shape error by 83% and the median position error by 72%.
Paper: https://groups.csail.mit.edu/rrg/papers/OkLiu19icra.pdf
We represent objects as ellipsoids and infer their parameters using three sources of information – bounding box detections, image texture, and semantic knowledge – to overcome the observability problem in ellipsoid-based SLAM under common forward-translating vehicle motions. Each bounding box provides four planar constraints on an object surface and we add a fifth planar constraint using the texture on the objects
along with a semantic prior on the shape of ellipsoids. We demonstrate ROSHAN in simulation where we outperform the baseline, reducing the median shape error by 83% and the median position error by 72%.
Deep Inference for Covariance Estimation: Learning Gaussian Noise Models for State estimation (2018)

click for full network
Deeply learned covariance estimation method that models measurement uncertainty
Paper: https://groups.csail.mit.edu/rrg/papers/LiuOk18icra.pdf
Video: https://youtu.be/GyapQn5Rhz0
We introduce Deep Inference for Covariance Estimation (DICE), which utilizes a deep neural network to predict the covariance of a sensor measurement from raw sensor data. We show that given pairs of raw sensor measurement and groundtruth measurement error, we can learn a representation of the measurement model via supervised regression on the prediction performance of the model, eliminating the need for handcoded features and parametric forms. Our approach is sensor-agnostic, and we demonstrate improved covariance prediction on both simulated and real data.
Paper: https://groups.csail.mit.edu/rrg/papers/LiuOk18icra.pdf
Video: https://youtu.be/GyapQn5Rhz0
We introduce Deep Inference for Covariance Estimation (DICE), which utilizes a deep neural network to predict the covariance of a sensor measurement from raw sensor data. We show that given pairs of raw sensor measurement and groundtruth measurement error, we can learn a representation of the measurement model via supervised regression on the prediction performance of the model, eliminating the need for handcoded features and parametric forms. Our approach is sensor-agnostic, and we demonstrate improved covariance prediction on both simulated and real data.
Simultaneous Tracking and Rendering: Real-time Monocular Localization for MAVs (2016)

click to enlarge
Real-time monocular camera-based localization in known environments
Paper: https://groups.csail.mit.edu/rrg/papers/Ok16icra.pdf
Video: https://youtu.be/p4ZEVVp77ds
We render virtual images of the environment and track camera images with respect to them using a robust semi-direct image alignment technique. Our main contribution is the decoupling of camera tracking from virtual image rendering, which drastically reduces the number of rendered images and enables accurate full camera-rate tracking without needing a high-end GPU.
Paper: https://groups.csail.mit.edu/rrg/papers/Ok16icra.pdf
Video: https://youtu.be/p4ZEVVp77ds
We render virtual images of the environment and track camera images with respect to them using a robust semi-direct image alignment technique. Our main contribution is the decoupling of camera tracking from virtual image rendering, which drastically reduces the number of rendered images and enables accurate full camera-rate tracking without needing a high-end GPU.
Multi-Level Mapping: Real-time Dense Monocular SLAM (2016)

click to enlarge
Real-time dense monocular mapping using quad-trees
Paper: http://groups.csail.mit.edu/rrg/papers/greene_icra16.pdf
Video: https://www.youtube.com/watch?v=qk2ViPVxmq0
We present a method for Simultaneous Localization and Mapping (SLAM) using a monocular camera that is capable of reconstructing dense 3D geometry online without the aid of a graphics processing unit (GPU). Our key contribution is a multi-resolution depth estimation and spatial smoothing process that exploits the correlation between low-texture image regions and simple planar structure to adaptively scale the complexity of the generated keyframe depthmaps to the texture of the input imagery.
Paper: http://groups.csail.mit.edu/rrg/papers/greene_icra16.pdf
Video: https://www.youtube.com/watch?v=qk2ViPVxmq0
We present a method for Simultaneous Localization and Mapping (SLAM) using a monocular camera that is capable of reconstructing dense 3D geometry online without the aid of a graphics processing unit (GPU). Our key contribution is a multi-resolution depth estimation and spatial smoothing process that exploits the correlation between low-texture image regions and simple planar structure to adaptively scale the complexity of the generated keyframe depthmaps to the texture of the input imagery.
Monocular Image Space Tracking on a Computationally Limited MAV (2015)
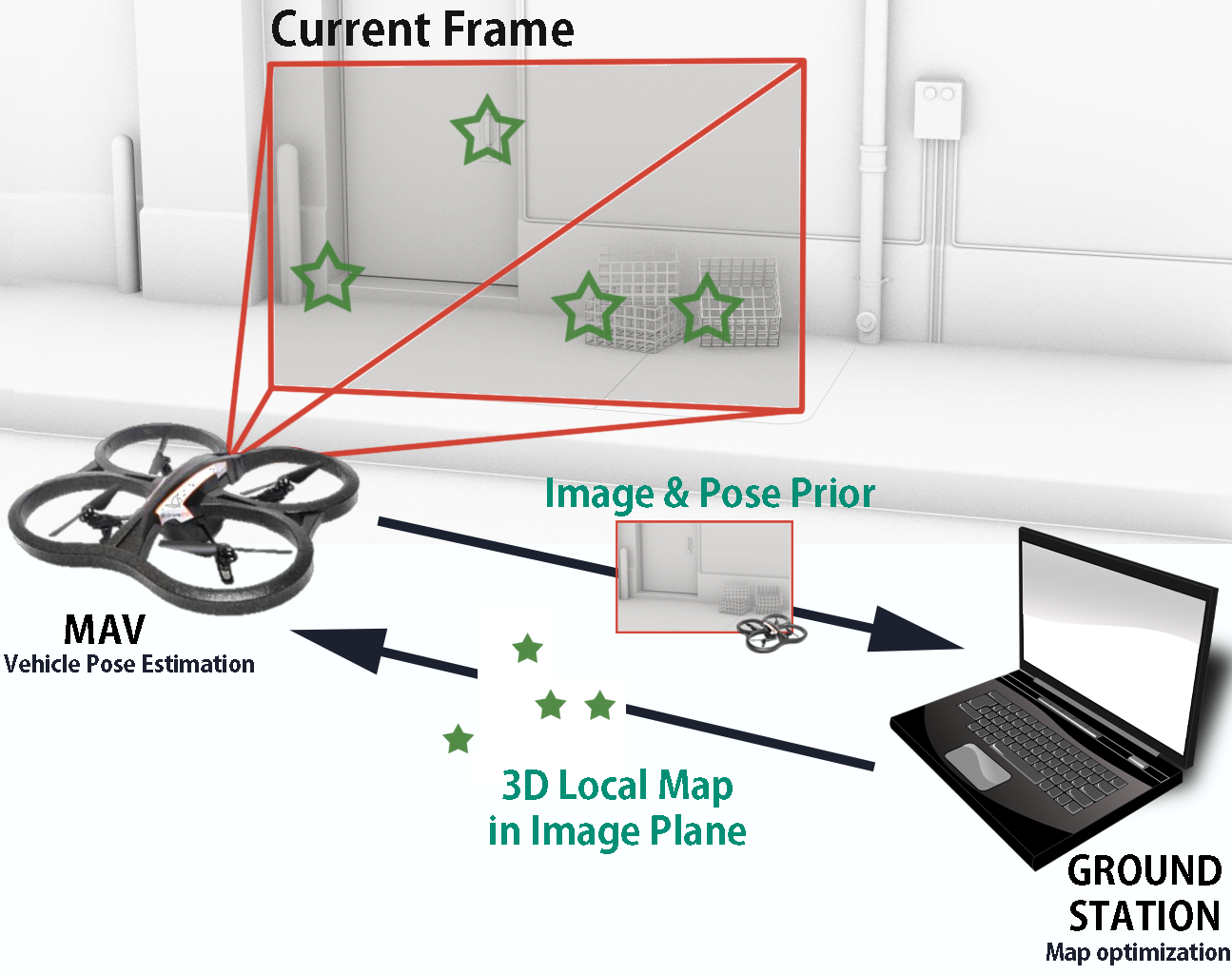
click to enlarge
Monocular camera-inertial based navigation for computationally limited micro air vehicles
Paper: http://www.cc.gatech.edu/~dellaert/pub/Ok15icra.pdf
Video: https://www.youtube.com/watch?v=VWWvjSHZCNo
Our approach is derived from the recent development of parallel tracking and mapping algorithms, but unlike previous results, we show how the tracking and mapping processes operate using different representations. The separation of representations allows us not only to move the computational load of full map inference to a ground station, but to further reduce the computational cost of on-board tracking for pose estimation.
Paper: http://www.cc.gatech.edu/~dellaert/pub/Ok15icra.pdf
Video: https://www.youtube.com/watch?v=VWWvjSHZCNo
Our approach is derived from the recent development of parallel tracking and mapping algorithms, but unlike previous results, we show how the tracking and mapping processes operate using different representations. The separation of representations allows us not only to move the computational load of full map inference to a ground station, but to further reduce the computational cost of on-board tracking for pose estimation.